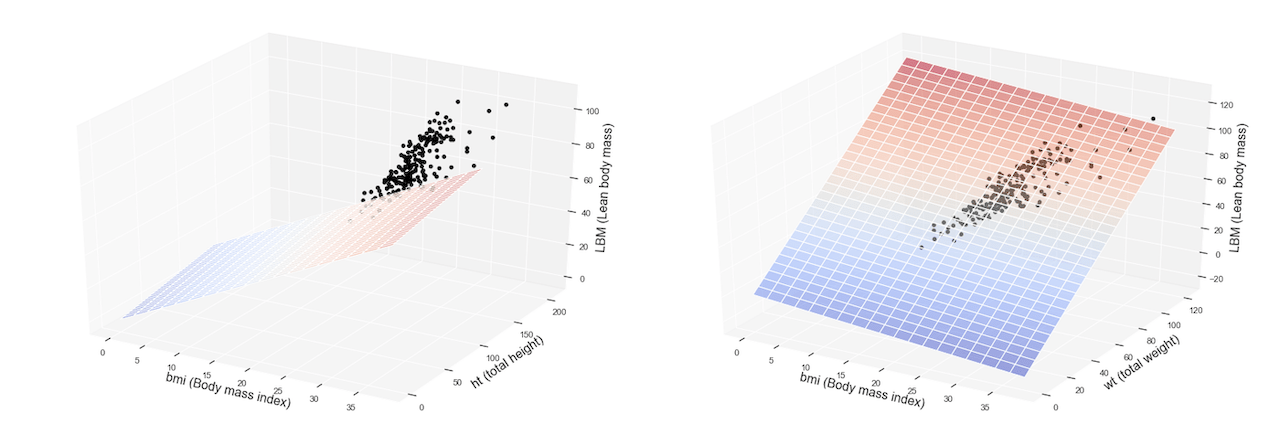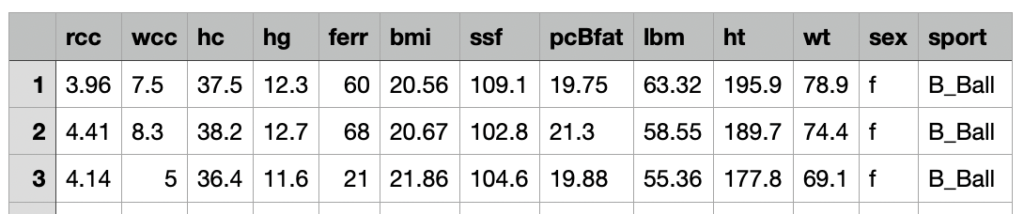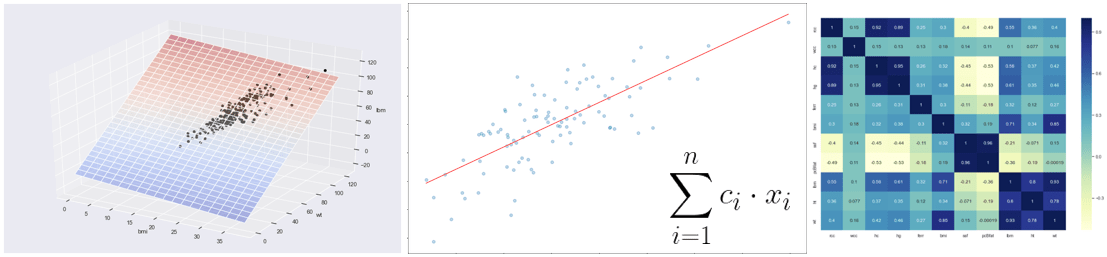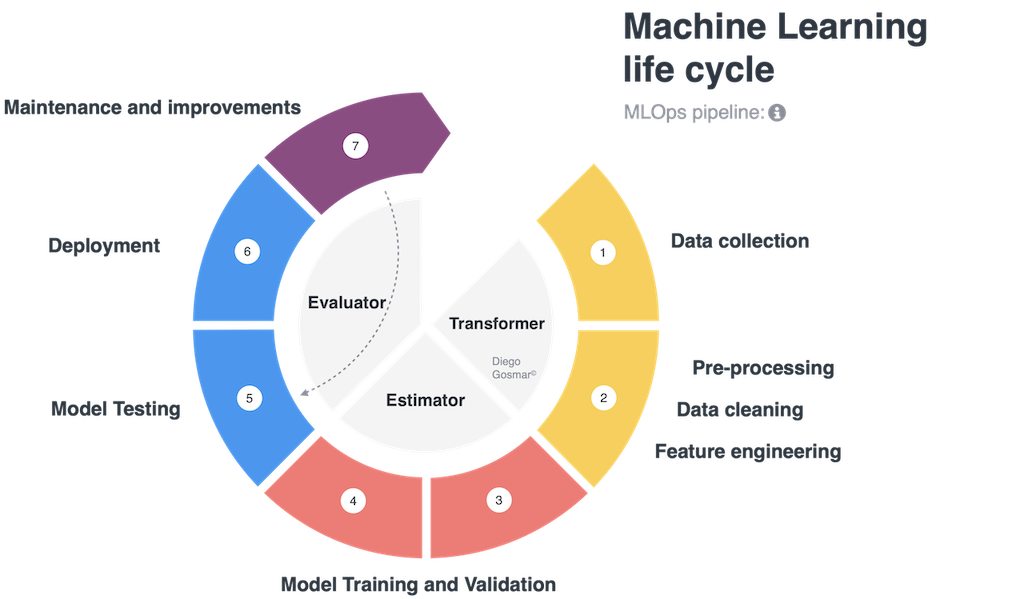
Con il crescente utilizzo delle tecniche di Machine Learning (ML) in varie industry, stiamo assistendo ad un aumento del numero di progetti e della loro complessità. Questo genera da un lato l’esigenza di maggiore governance ovvero capacità di orchestrare e controllare la catena di sviluppo e rilascio sull’intera ciclo di vita del ML (preprocessing, model training, testing, deployment) e dall’altro lato l’esigenza di scalabilità, ovvero riuscire a replicare in maniera efficiente parti intere del processo per gestire molteplici modelli di ML (Machine Learning).
Una recente ricerca in USA, effettuata per comprendere le tendenze relative al mondo del Machine Learning per il 2021, ha elaborato un sondaggio effettuato su un campione significativo di 400 aziende di varia dimensione: il 50% di queste sta gestendo attualmente più di 25 modelli di ML e il 40% del totale gestisce oltre 50 modelli di ML. Tra le organizzazioni di grande dimensione (oltre 25.000 collaboratori) il 41% di esse possiede oltre 100 algoritmi di ML in produzione!
Leggi tutto “Scalabilità per MLOps”