

As described on the official OpenAI website, Whisper is an Automatic Speech Recognition (ASR) system trained on 680,000 hours of supervised multilingual and multitasking data collected from around the web.
The use of such a large and diverse data set leads to greater robustness in speech recognition even in the presence of particular accents, accentuated background noise and specific or technical language. It also allows for transcription into multiple languages, as well as translation from those languages into English.
OpenAI’s goal with Whisper is to provide open source models and inference (prediction) code that provide a foundation for developing useful market applications as well as support for further research into speech processing and transcription solutions.
The machine learning models adopted for Whisper are based on the concept of a Transformer which adopts a well-established encoder-decoder system (I have already described the Transformers in a dedicated chapter of my Machine Learning book).
Let’s see it in action now by deploying few lines of Python code that allow us to use the Whisper models to perform a speech-to-text conversion.
First, let’s import the library to use whisper and load one of the models to convert for example a conversation between a customer and customer care operator:
#import library
import whisper
#Let’s use one of the Whisper models:
model = whisper.load_model(“base“)
result = model.transcribe(‘/path/conversation.wav’)
print(result[“text”])
Here’s an excerpt from the conversation that Whisper was able to convert to text:
Hello, and thank you for calling the bank. This is Ashley speaking. How may I help you today? Hi I just need to cancel my card. I was a debit card and a credit card. It's my card was broken into so I need a cancel everything. Okay, and who am I speaking with? Oh, and this is Melissa Bivens B-I-D-E-N-S B-I-D as in dog No, Z is in Perfect. Any words? Voice Okay, B-I-Z-V-E and then can you spell that last card again for me? I'm on the start over a B as in a boy. I-Z-Z-V-E as in everything and and Perfect and your first name one more time just since we sent so much time on that last name Melissa, perfect. Thank you so much...
The model.transcribe method loads the model version called “base”, however Whisper provides N models, which have been trained with many different parameters. Here is a list:
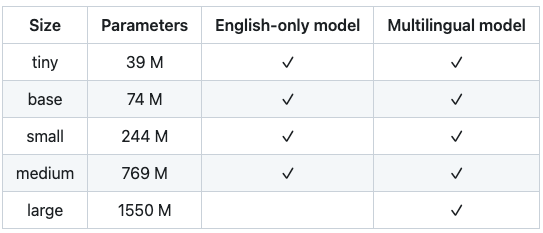
It should be noted that an additional model called large-v2 was released and trained with 2.5 epochs higher than the large V1 in the table in December 2022.
The following graphs show the performance trend of the large-v2 model, as regards WER* and Accuracy.
*WER stands for Word Error Rate and is a fundamental parameter for evaluating the effectiveness of a voice recognition system (obviously the lower the WER, the greater the quality of the solution).
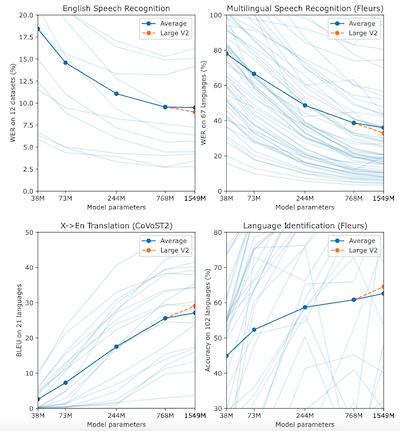
Compared to the models mentioned above, it is useful to underline that “tiny” and “base” are simpler models (so to speak) or trained on a smaller number of parameters: they will have a higher WER, but will be able to convert a voice conversation into text very quickly. The higher models (small, medium, large) will be gradually more accurate and will have lower WER, however at the expense of transcription speed.
Therefore, with the same computing power, as we use higher Whisper models we will obtain higher quality voice-to-text conversions, however using more processing time.
It is therefore evident that the model must be chosen according to the needs: for example, if I simply want to convert a voice conversation into text without any need to carry out this processing quickly – for example I want to carry out a transcription to subsequently carry out some analyses – then I can choose medium or large models.
Conversely, if I had to convert speech in real time, to immediately display the text and I didn’t have extreme computing power at my disposal, then I would be better off choosing a whisper tiny or basic model.
We can also try to carry out the transcription starting from a youtube video. In the following example we take one of the public videos clip from the Gladiator movie.
Let’s extract only the audio part first:
#Importing Pytube library
import pytube
#Reading the above Gladiator movie Youtube link
video = ‘https://www.youtube.com/watch?v=hE9Lmsmzhnw’
data = pytube.YouTube(video)
#Converting and downloading as MP4 file
audio = data.streams.get_audio_only()
audio_downloaded = audio.download()
Afterwards, let’s apply the “small” model and display the result:
model = whisper.load_model(“small”)
text = model.transcribe(audio_downloaded)
#printing the transcribe
text[‘text’]
" MUSIC CHEERING Guys! Guys! MUSIC Your fame is well-deserved, Spaniards. I don't think there's ever been a gladiator to match you. Just for this young man, he insists you are Hector Reborn. What was the turkish? Why doesn't the hero reveal himself and tell us all your real name? You do have a name. My name is Gladiator. How dare you show your back to me? Slave! Will you remove your helmet and tell me your name? My name is Maximus Decimus Meridius. Commander of the armies of the North, general of the Felix legions. Loyal servant to the true emperor, Marcus Aurelius. Father to a murdered son, husband to a murdered wife. And I will have my vengeance in this life or the next. Ham! CHEERING CHEERING CHEERING Arm! Brace! CHEERING MUSIC MUSIC MUSIC MUSIC MUSIC MUSIC MUSIC MUSIC MUSIC"
Not bad as a result!
For those interested in better understanding what’s behind it, this is the Whisper’s encoder-decoder-based Transformer architecture:
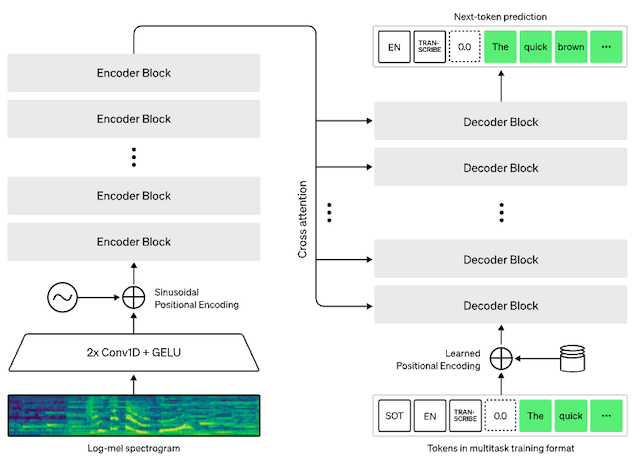
The incoming audio is broken into 30-second chunks, converted into a log-Mel spectrogram, then passed through an encoder. A decoder is trained to predict the matching text caption, mixed with special tokens that use the single pattern to perform specific tasks, such as language identification, sentence-level timestamps, multilingual speech transcription, or speech translation in English.
Incidentally, we have already explored the use of algorithms based on MEL in this previous article, where we talked about MFCC (Mel Frequency Cepstral Coefficient) in combination with Neural Networks for speech recognition applications.
This time OpenAI with Whisper has adopted a similar methodology, but with more advanced Machine Learning techniques moving from the use of pure neural networks to Transformers (attention is all you need)!
Back to the initial conversation transcription, the following code allows us to decode the first 30-second chunk of the conversation and detect the language as well.
model = whisper.load_model(“base”)
#load the audio and adapt it to fit 30 seconds
audio = whisper.load_audio(‘/Users/diego.gosmar/Diego/AI/Whisper/conversation1.wav’)
audio = whisper.pad_or_trim(audio)
#make log-Mel spectrogram
mel = whisper.log_mel_spectrogram(audio).to(model.device)
#detect the language and print it
_, probs = model.detect_language(mel)
print(f”Detected language: {max(probs, key=probs.get)}”)
#decode the initial 30 seconds of audio
options = whisper.DecodingOptions(fp16 = False)
result = whisper.decode(model, mel, options)
#print the results
print(result.text)
Detected language: en Hello and thank you for calling the bank. This is Ashley speaking. How may I help you today? Hi, I just need to cancel my card. I have a debit card and a credit card. It's my card...
Initially Python 3.9.9 and the PyTorch 1.10.1 machine learning framework were used to train and test the models, but the code base should also be compatible with other versions of Python and the latest PyTorch versions. A part of the code also depends on some specific Python libraries, in particular OpenAI’s tiktoken for their rapid tokenization implementation (by the way, we have already covered the embedding and tokenization issues in a previous article dedicated to the use of neural networks for sentiment analysis).
Do you want to learn more about these topics?
Here is an interesting read on Machine Learning and AI.
