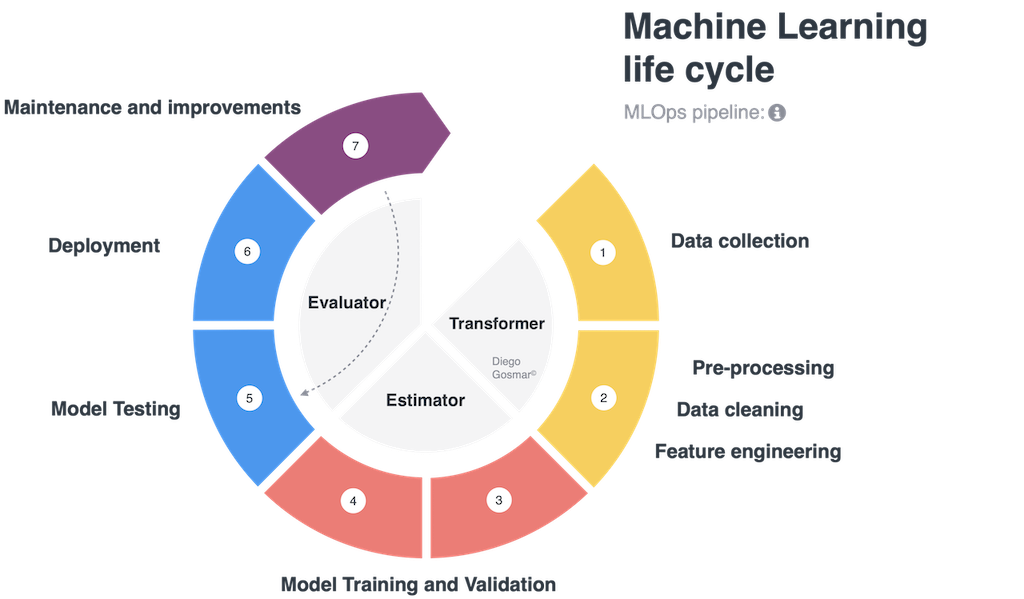
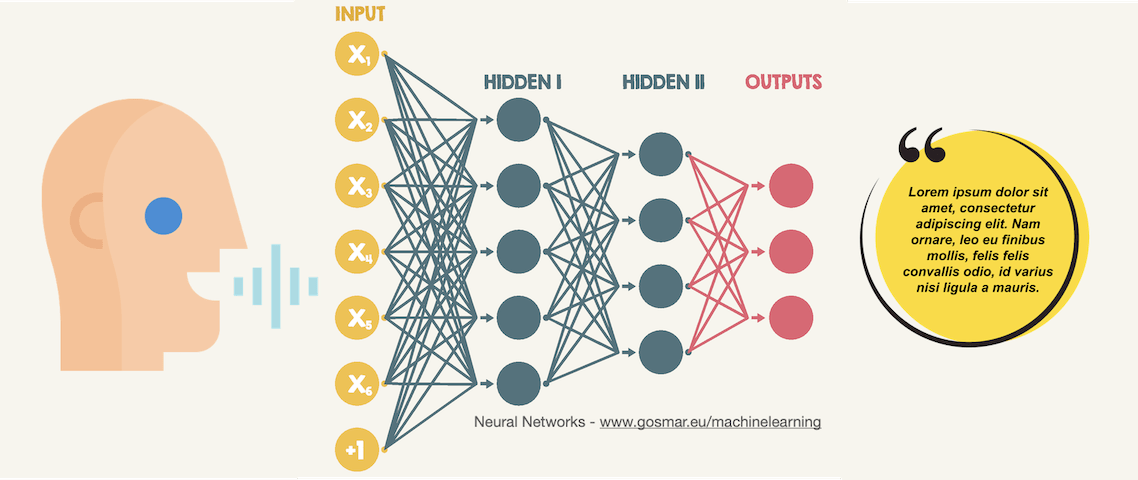
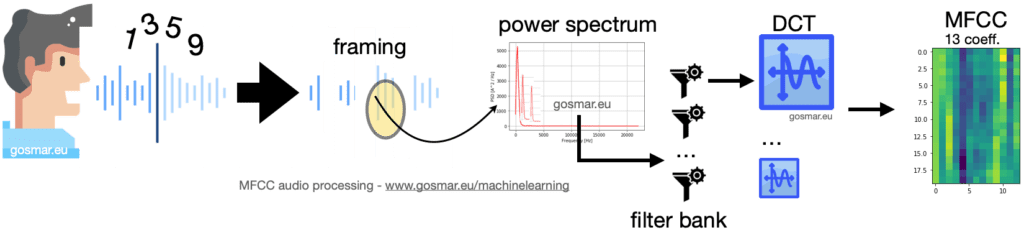
As described on the official OpenAI website, Whisper is an Automatic Speech Recognition (ASR) system trained on 680,000 hours of supervised multilingual and multitasking data collected from around the web.
The use of such a large and diverse data set leads to greater robustness in speech recognition even in the presence of particular accents, accentuated background noise and specific or technical language. It also allows for transcription into multiple languages, as well as translation from those languages into English.
Continue reading “OpenAI Whisper: the Open Source ASR based on Transformers”