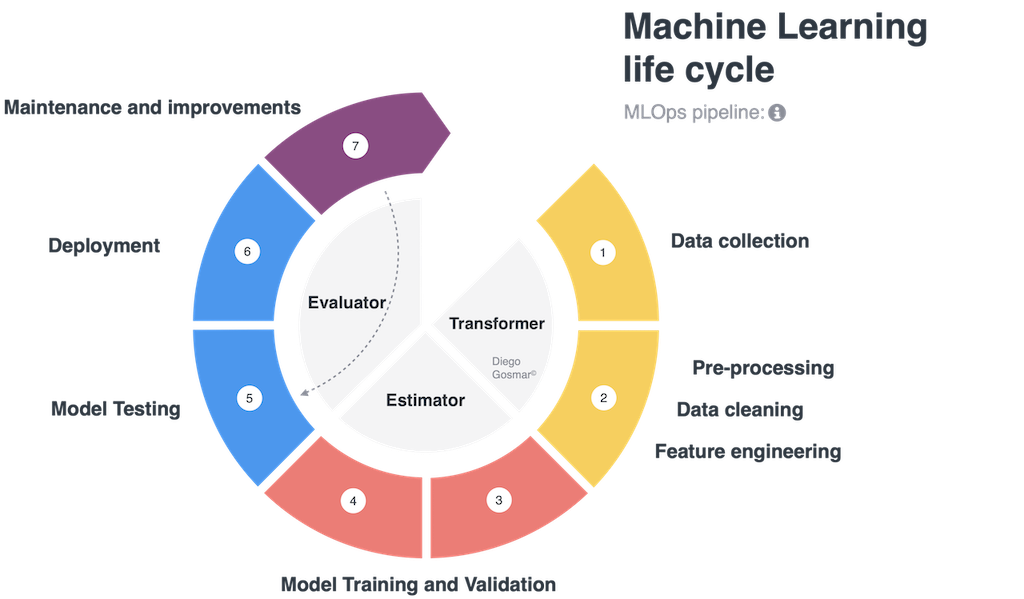
Nowadays Machine Learning (ML) techniques are applied in various industries, along with an increasing number of projects and complexity. This generates on one hand the need for greater governance, i.e. the ability to orchestrate and control the development and deploy over the entire ML life cycle (preprocessing, model training, testing, deployment), on the other hand, the need for scalability, i.e. being able to efficiently replicate entire parts of the process, in order to manage multiple ML models.
A recent USA research, carried out to understand the Machine Learning trends for 2021, has conducted a survey on a significant sample of 400 companies: 50% of these are currently managing more than 25 models of ML and 40% of the total runs over 50 ML models. Among large organizations (over 25,000 collaborators) 41% of them turned on to have over 100 ML algorithms in production!
Continue reading “MLOps scalability”